建模指南
DDM为企业提供有多种常用的数据库模型设计场景应用,旨在帮助企业高效、精准地构建和管理数据模型。本章节将深入剖析DDM工具在数据仓库模型设计与管理,以及应用系统关系型数据库模型设计与管控方面的强大功能与实践指南。
数仓模型
DDM提供了全面的数据仓库模式管理功能,支持企业根据业务需求构建符合规范的数据仓库架构。通过DDM,企业可以轻松实现数据的分层存储、缓慢变化维的处理,以及跨层表映射的编辑,从而确保数据仓库中的数据既规范又易于分析。此外,DDM还提供了丰富的数仓专用特性,如数据仓库模式管理、缓慢变化维模板应用等,进一步提升了数据仓库的灵活性和可扩展性。
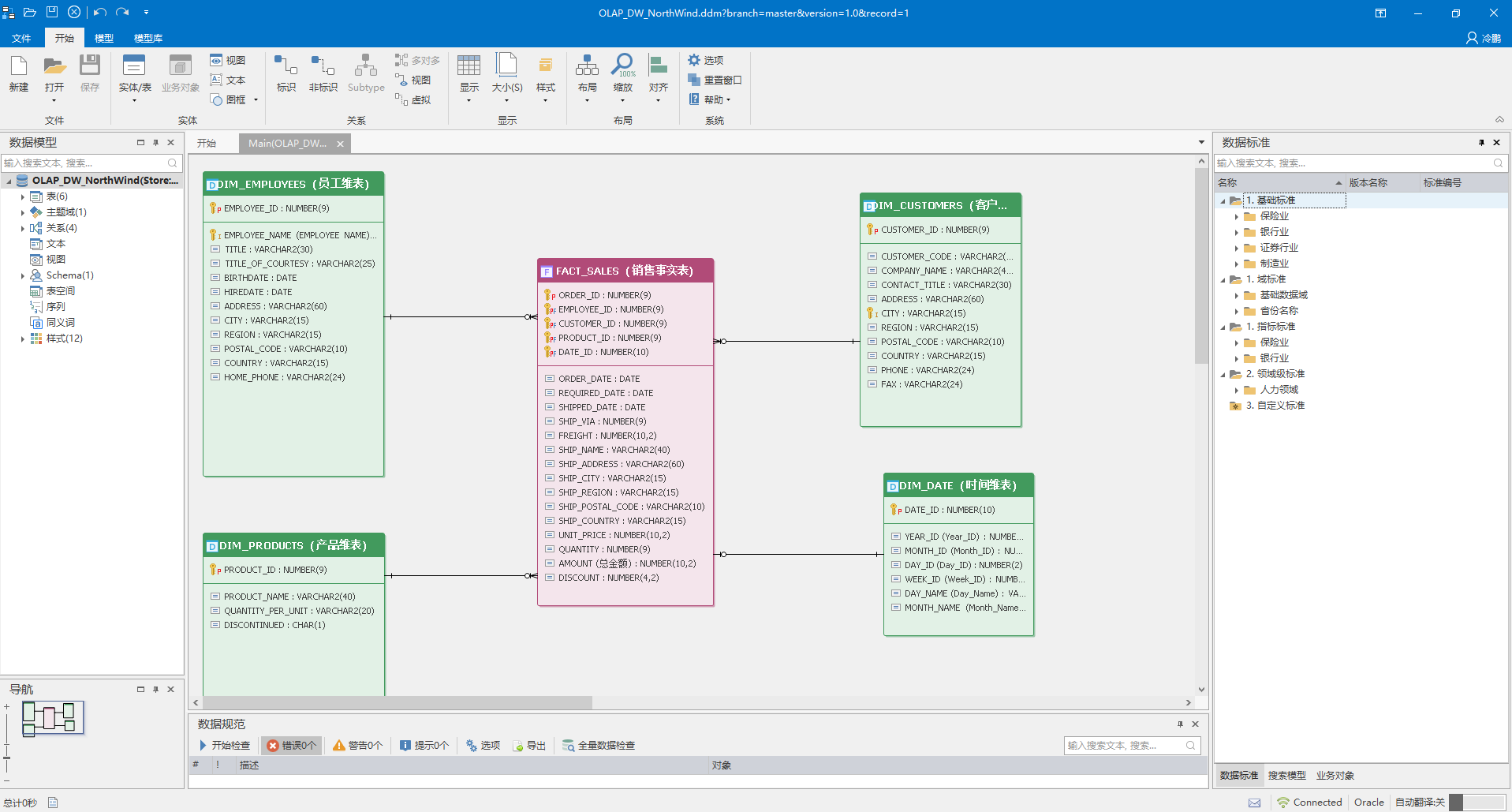
- 数据仓库专用特性
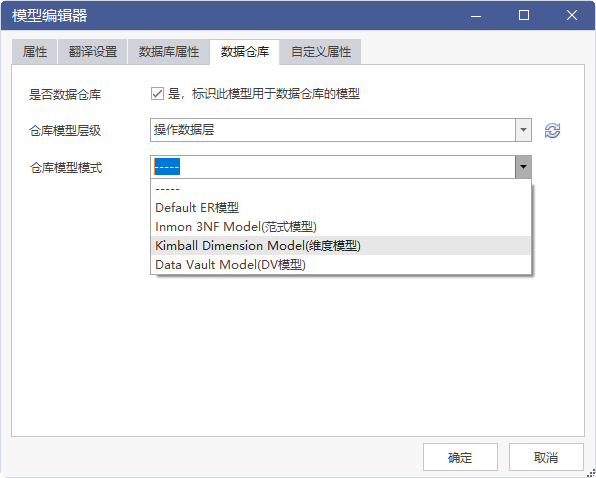
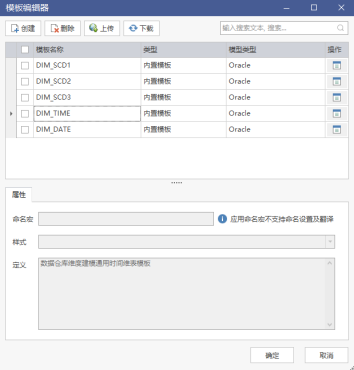
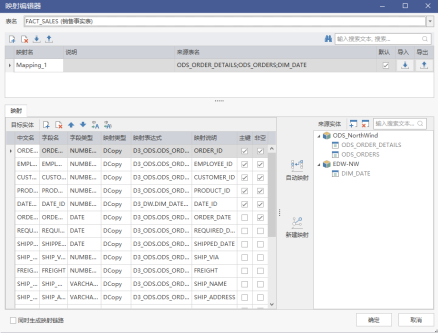
模型概述
数据仓库模型是一种用于整合和存储大量历史数据的结构,主要服务于商业智能(BI)和数据分析领域。与操作型数据库不同,其重点在于提供高效的数据查询和分析能力,而非处理日常事务。常见的数据仓库建模方法包括星型模式、雪花型模式和 DataVualt 建模等,它们各自具有独特的结构和特点,以适应不同的数据场景和分析需求。
-
维度建模--星型模型

星型模型是一种非正规化的结构,其核心在于多维数据集的每个维度都直接与事实表相连接,不存在渐变维度,这使得数据在一定程度上存在冗余。然而,正是这种数据冗余的特性,使得许多统计查询无需进行外部连接操作,从而在一般情况下,其查询效率相对雪花型模型更高。这种模型结构简单明了,易于理解和实现,尤其适用于对查询性能要求较高、维度相对固定且分析需求较为明确的场景,如一些企业的销售数据分析等,能够快速响应用户的查询请求,为决策提供及时的数据支持。
- 维度建模--雪花模型
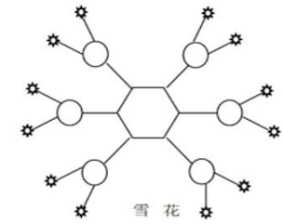
雪花模型是对星型模型的扩展,它对星型模型的维表进一步层次化处理。原有的各维表可能被扩展为小的事实表,从而形成一些局部的 “层次” 区域,这些被分解的表都连接到主维度表而不是事实表。虽然这种结构在一定程度上减少了数据冗余,但由于维度表、事实表之间的连接增多,导致其在性能方面相对较低。不过,雪花模型在数据关系复杂、需要灵活分析的场景下具有优势,例如在复杂的供应链管理系统中,能够更细致地表达各类数据之间的关系,满足多样化的分析需求,但对系统的性能和资源要求也相对较高。
- DataVualt建模
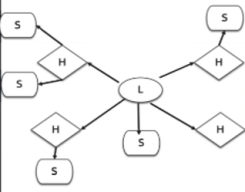
DataVualt 建模包含中心表(Hub)、链接表(Link)和卫星表(Satellite)三个关键部分。中心表作为唯一业务键的列表,用于唯一标识企业实际业务,是企业业务主体的集合;链接表则主要表示中心表之间的关系,通过它能够串联起整个企业的业务关联关系;卫星表用于存储历史的描述性数据,是数仓中数据的真正载体。这种建模方式适用于大规模、复杂的数据环境,能够有效地管理和组织海量数据,确保数据的完整性和可追溯性,为企业提供全面、准确的数据视图,支持深入的数据分析和决策制定。例如在大型金融机构中,可用于管理客户信息、交易记录等海量数据,帮助分析客户行为、风险评估等多方面业务。
模型分层
数据仓库模型通常采用分层架构,这种分层设计不仅有助于数据的规范化管理,还能提升数据处理的效率和灵活性。以下是数据仓库模型中常见的分层及其详细介绍:

-
ODS(操作数据存储层)
ODS层主要存放从源系统直接抽取的数据。这些数据在抽取过程中几乎不进行数据转换,以保持数据的原貌和完整性。ODS层的主要作用是为后续的数据处理提供快速的数据获取通道,并对数据进行初步的清洗和转换。由于它直接关联源系统,因此能够确保数据的实时性和准确性。
-
DW(数据仓库层)
DW层是数据仓库模型的核心层,它又可细分为以下几个子层:
-
DWD(明细数据层):DWD层对ODS层的数据进行进一步的清洗和转换,形成详细的明细数据。这些数据按照业务逻辑进行组织,为后续的数据分析和挖掘提供基础。
-
DWM(中间层):DWM层对DWD层的明细数据进行轻度汇总,以提升数据处理性能。这一层的数据通常是基于特定的业务需求进行聚合,以减少后续查询和分析时的计算量。
-
DWS(服务数据层):DWS层根据业务需求对DWM层的数据进行高度汇总,为数据分析提供服务。这一层的数据通常是经过精心设计和优化的,以满足前端应用对数据的需求。
-
ADS(应用数据层)
ADS层是根据具体业务需求为前端应用提供数据支持的层。它基于DW层的数据进行进一步的加工和处理,以满足报表展示、数据分析等具体业务需求。ADS层的数据通常是经过格式化和优化后的,以便于前端应用进行展示和分析。
样例说明
操作步骤
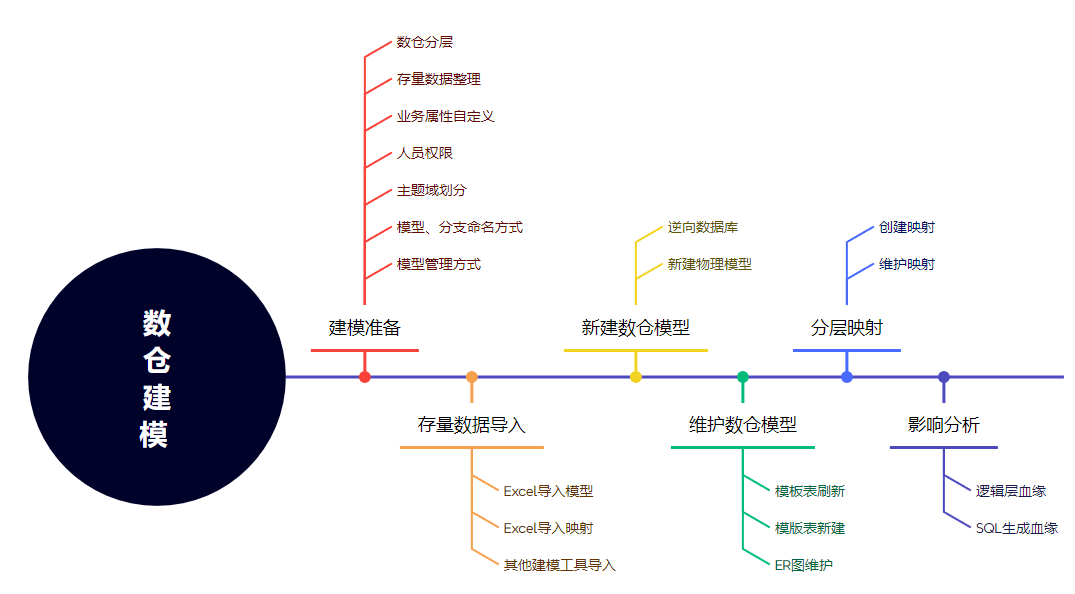
建模准备
业务属性自定义
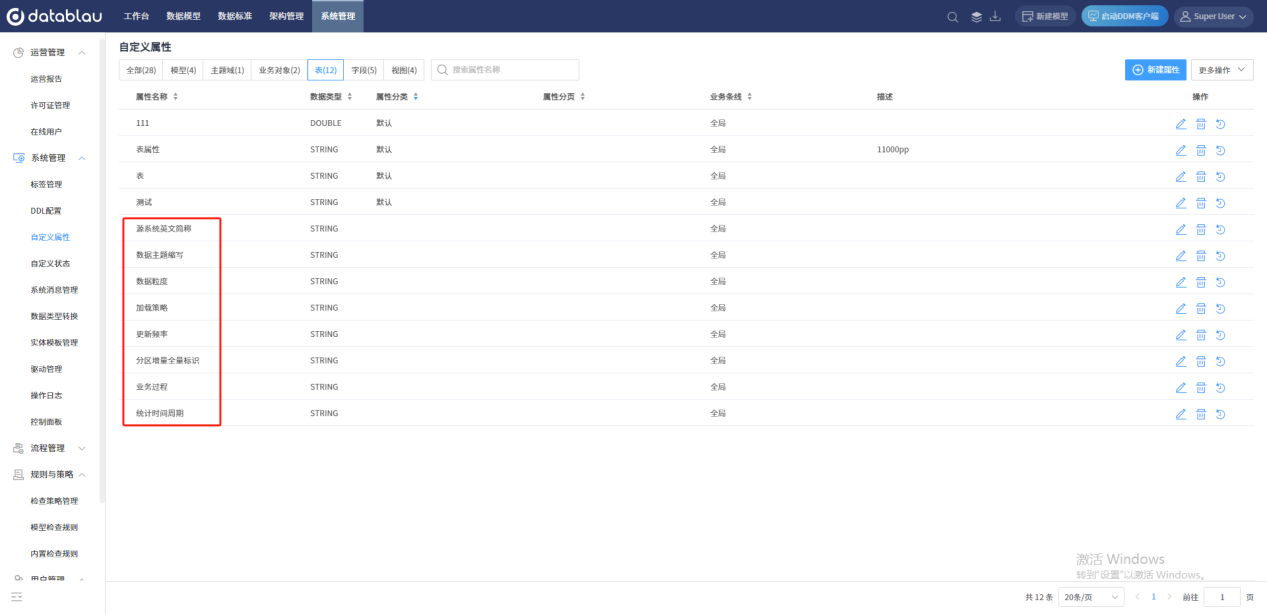
DDM支持的数仓原生属性并不足以满足丰富的业务场景以及多元化的客户需求,所以在实际建模前,需要业务人员险先整理DDM本身不具备的表、字段的属性,然后通过DDM自定义属性功能进行补全。例如:更新频率、更新周期等属性。
管理员在web端创建自定义属性,用来标识数仓的属性。
存量数据整理
使用DDM建模工具前,用户需要整理存量数仓建模的相关数据,可能是之前通过Excel维护的映射mapping关系,宽表数据等,也可能是在Erwin、PD等建模工具上维护的旧有模型。
人员权限
DDM本身对于模型、分支、模型目录(可以理解为应用系统)都有单独权限配置,支持配置只读、读写和管理员权限。
在建模前,需要用户考虑好对于模型的权限改如何分配。
模型、分支等命名方式
建模前需要规范模型、分支的命名方式,例如使用:数仓分层_应用系统 _负责人_更新时间来进行命名。
模型管理方式
DDM支持的模型管理方式是使用分支/版本进行管理,可以由不同的建模人员维护同一个模型,进行版本控制 ;也可以维护一个主线分支,然后不同的建模人员每人拉取Dev分支进行管理。
根据实际模型数量、业务需要、人员构成等客观因素,来灵活定义符合的管理方式。
存量数据导入
Excel导入模型
需要先在 客户端下载导入模版,然后将存量数据转换为DDM模型的导入模版。
导入Excel后,DDM会自动生成ER图。
Excel导入映射
模型导入完成后,可以通过Excel导入mapping映射关系,也是需要转换为DDM的格式。
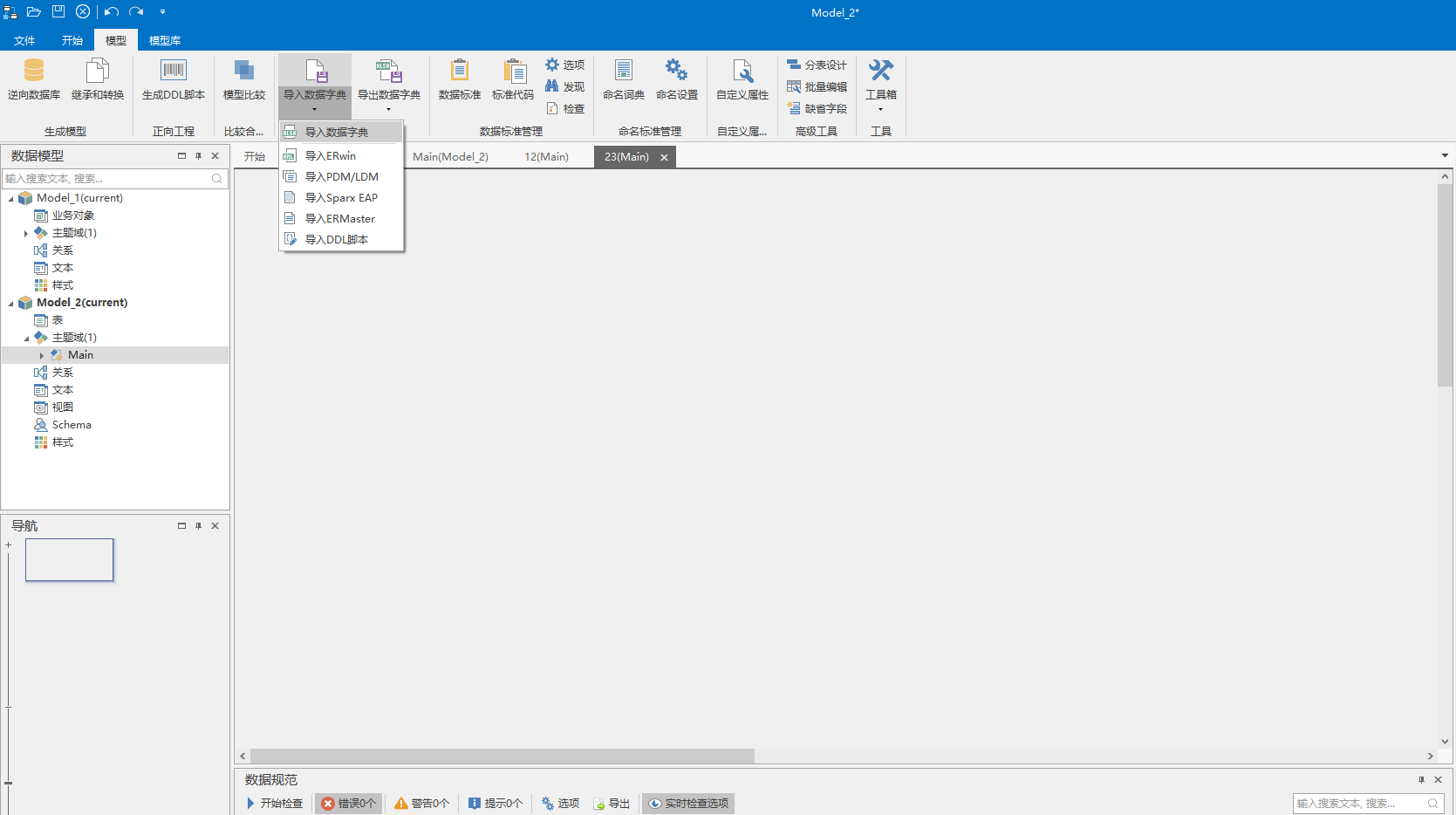
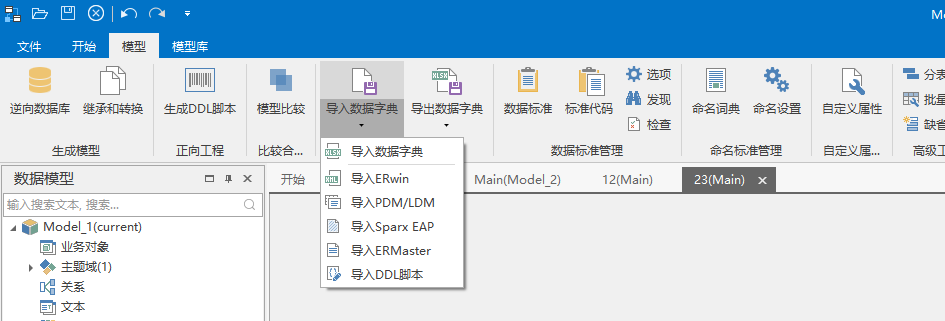
其他工具导入模型
可以通过其他建模工具 导入到DDM中。
新建数仓模型
逆向数据库
对于存量系统,DDM支持直接逆向数据库为 ER模型 。

新建物理模型
对于新建的系统,可以直接创建ER模型。
维护数仓模型
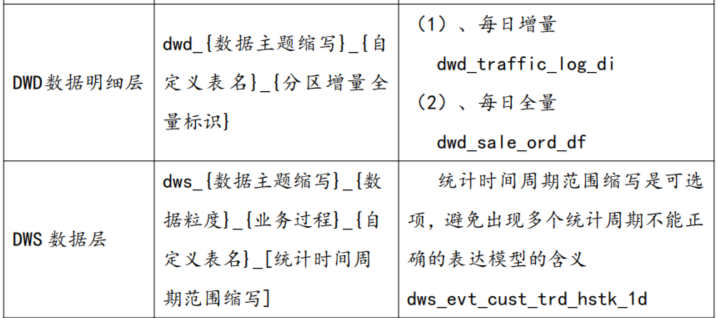
DDM支持用户使用表模版进行快速建模,表模板可以定义表的缺省字段、命名方式等内容。
可以使用模板表对存量表进行刷新,补充缺省字段等内容 。
管理员在客户端创建不同数仓分层的模板表。
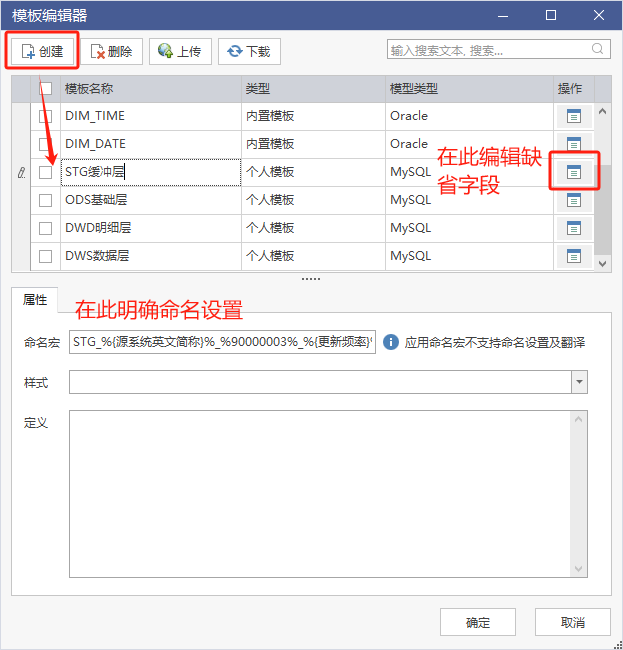
根据命名要求,输入命名宏。
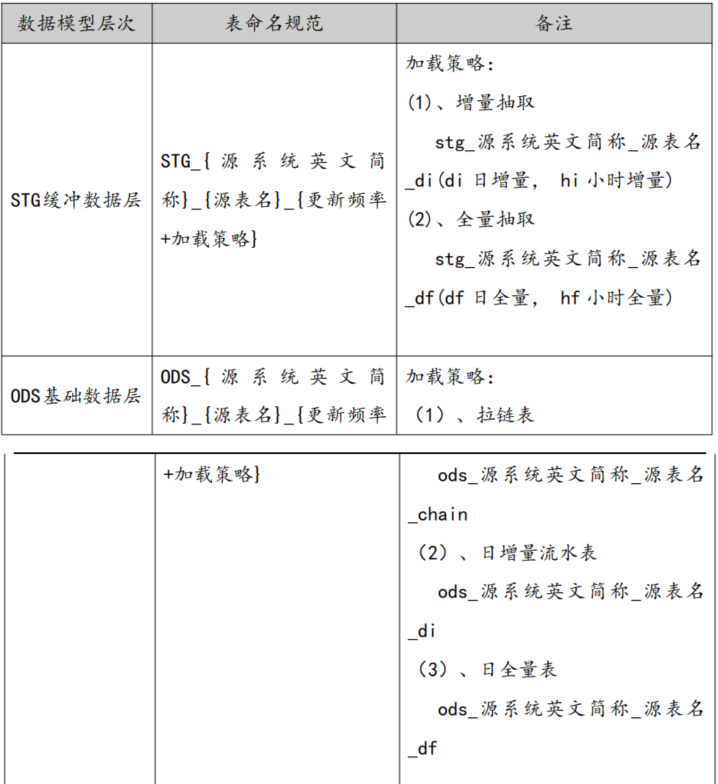
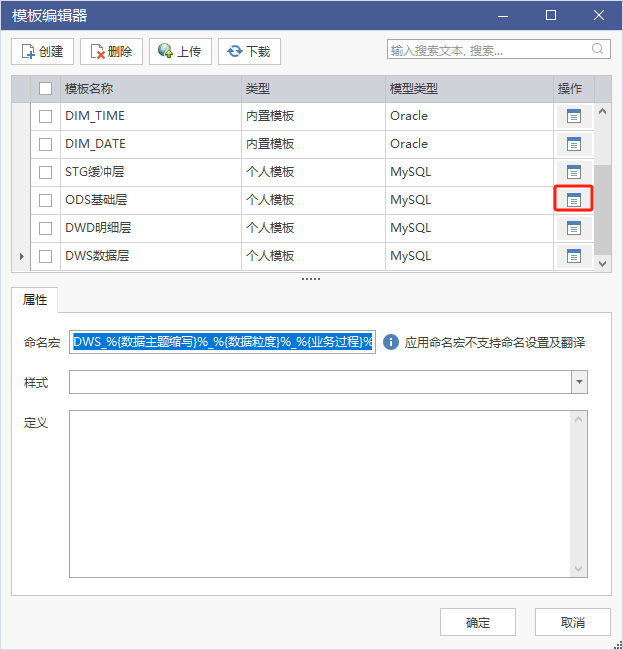
根据数仓要求补充缺省字段
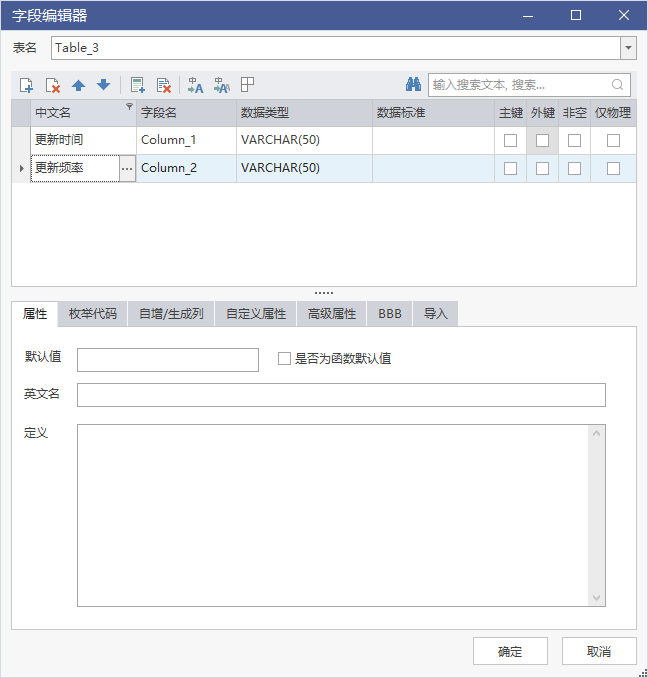
对于存量表,在自定义属性填写对应的值
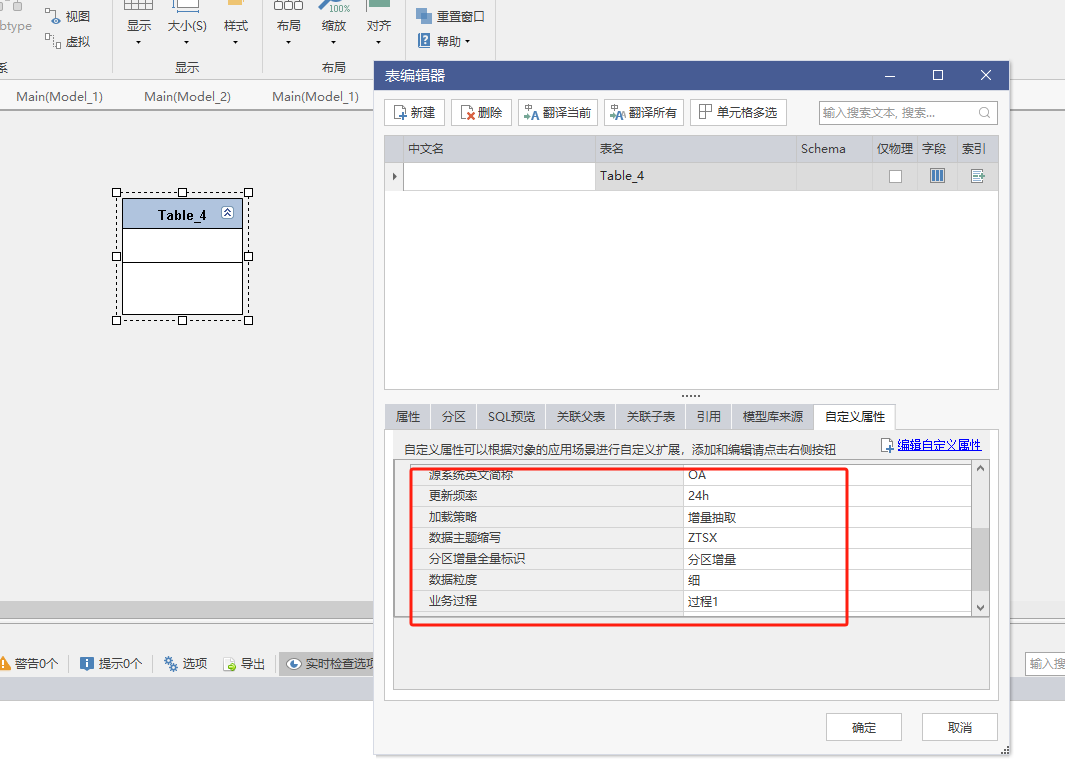
在画布上选中要刷新的表,点击对应的模板。
例如:我要将table_4刷新为STG缓冲表。我就选中table_4,再点击STG缓冲表这个模板。
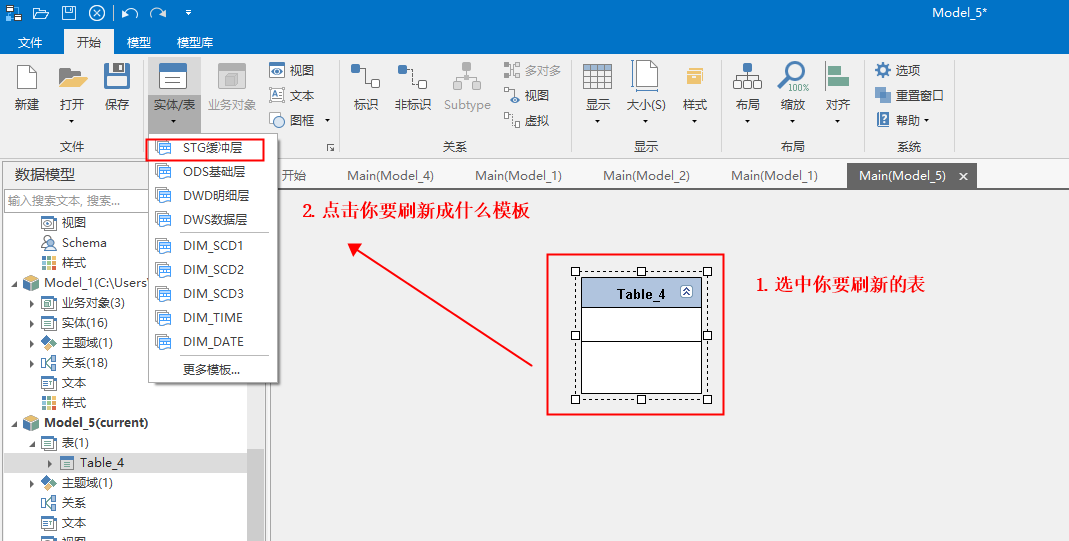
结果:

对于新建的表,可以直接拖拽一个模板表下来
例如:直接创建一个DWD表。
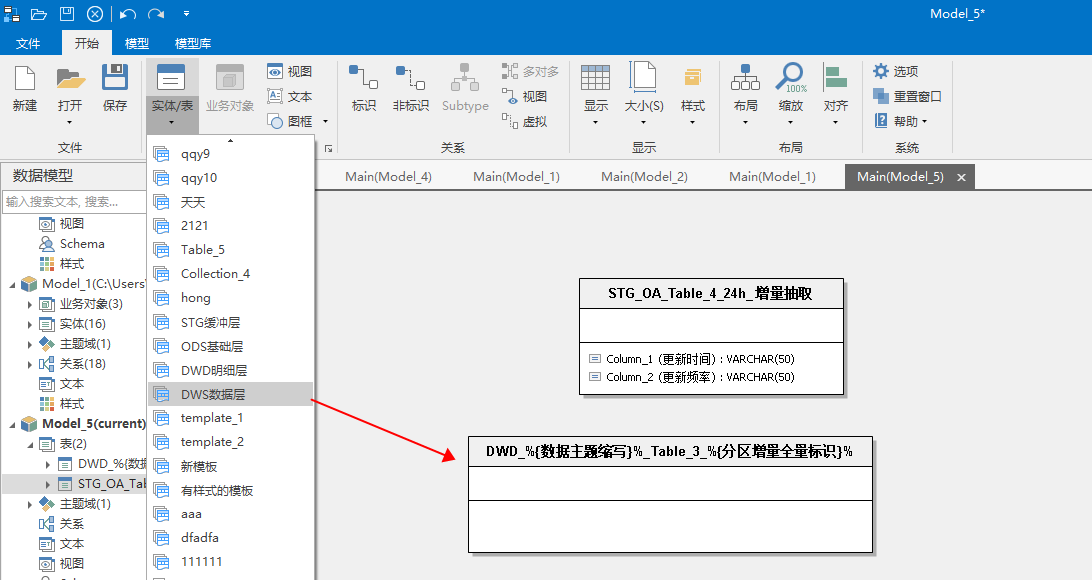
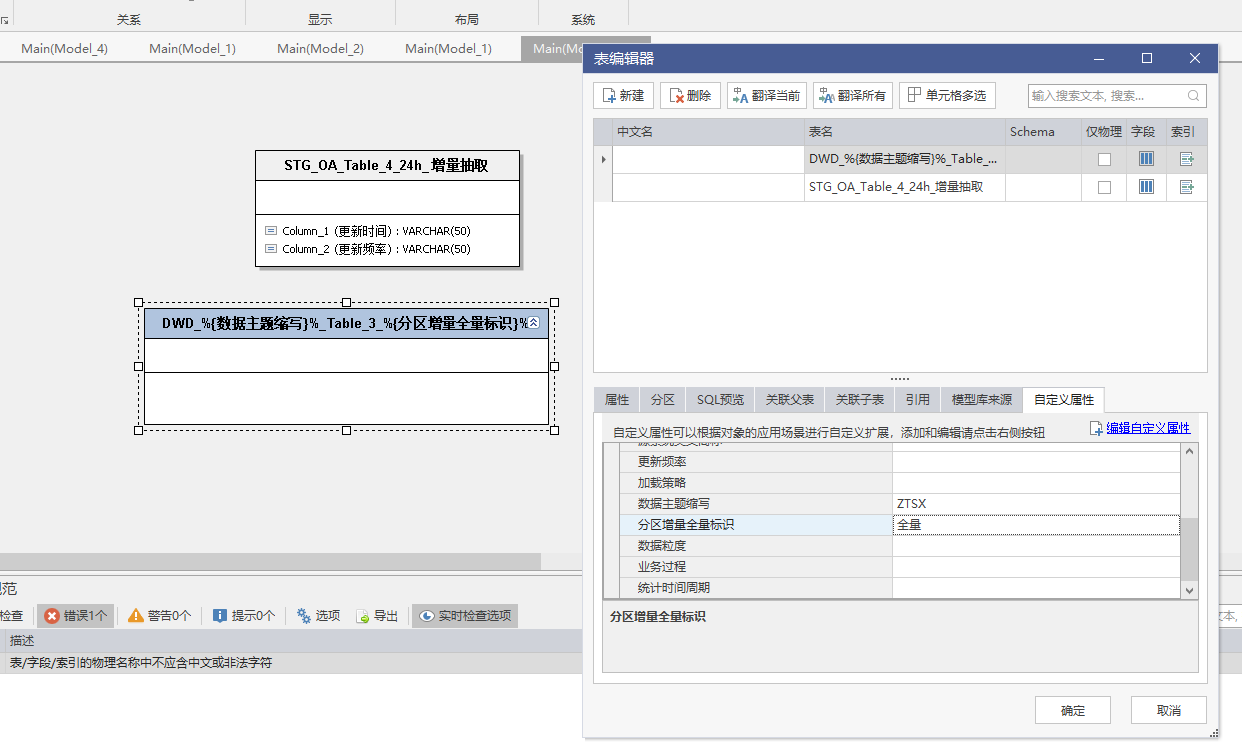
然后在表属性中添加数据主题缩写和分区增量全量标识这两个自定义属性。

分层映射
拖拽方式创建映射
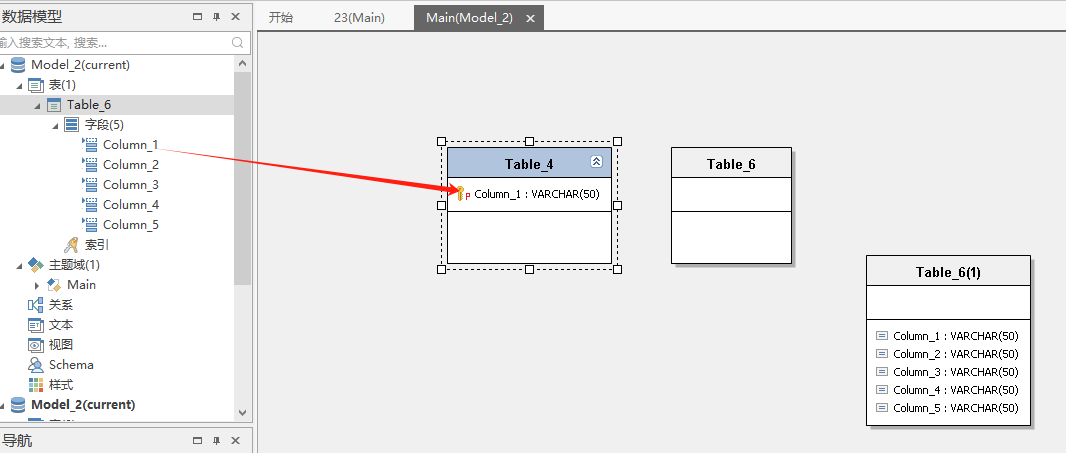
可以直接从左侧不同分层的模型上拖拽一个表到当前模型上,系统会自动建立mapping关系。
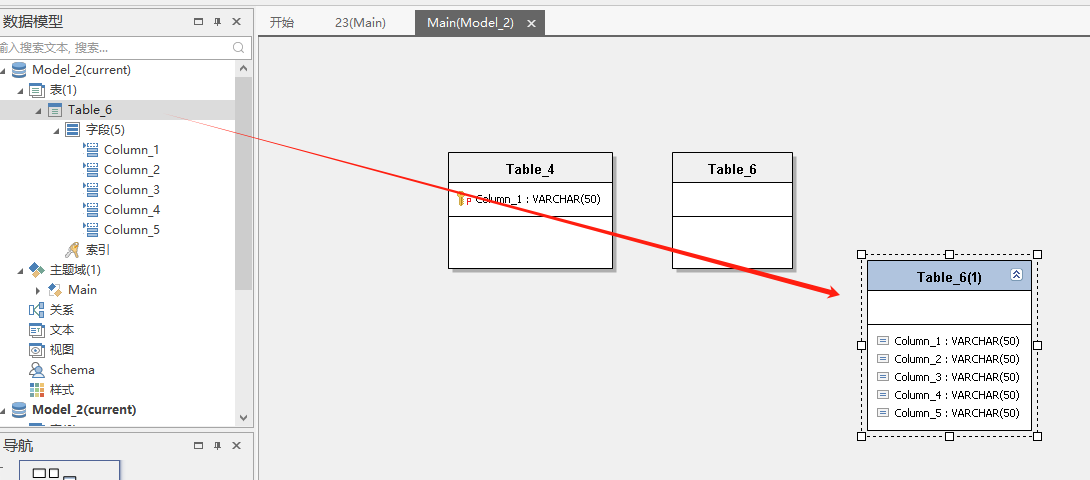
也可以拖动其他分层模型的字段到当前模型的表上。
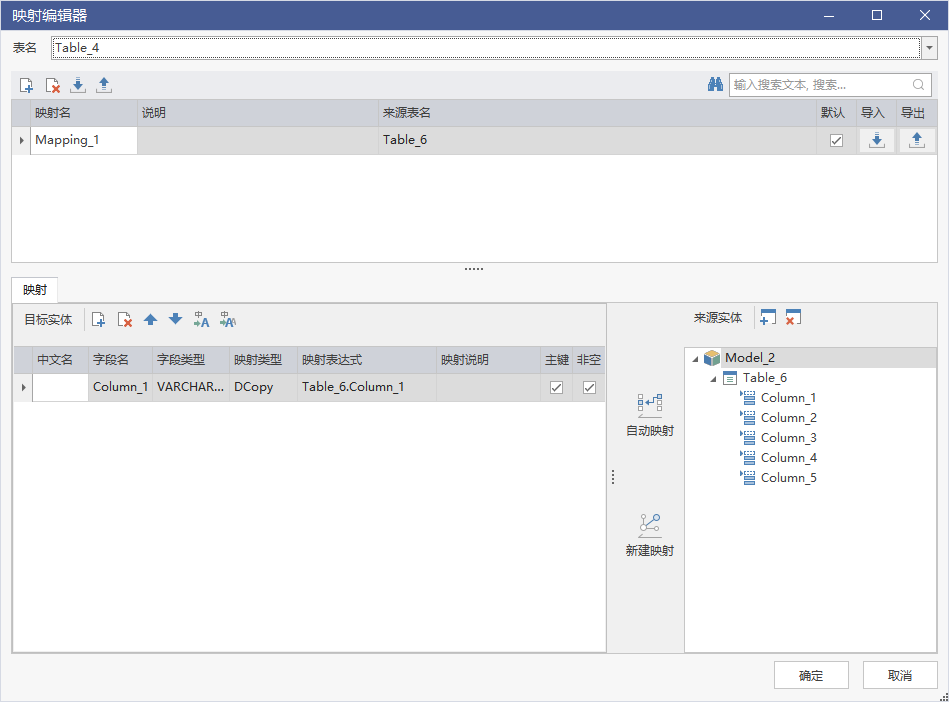
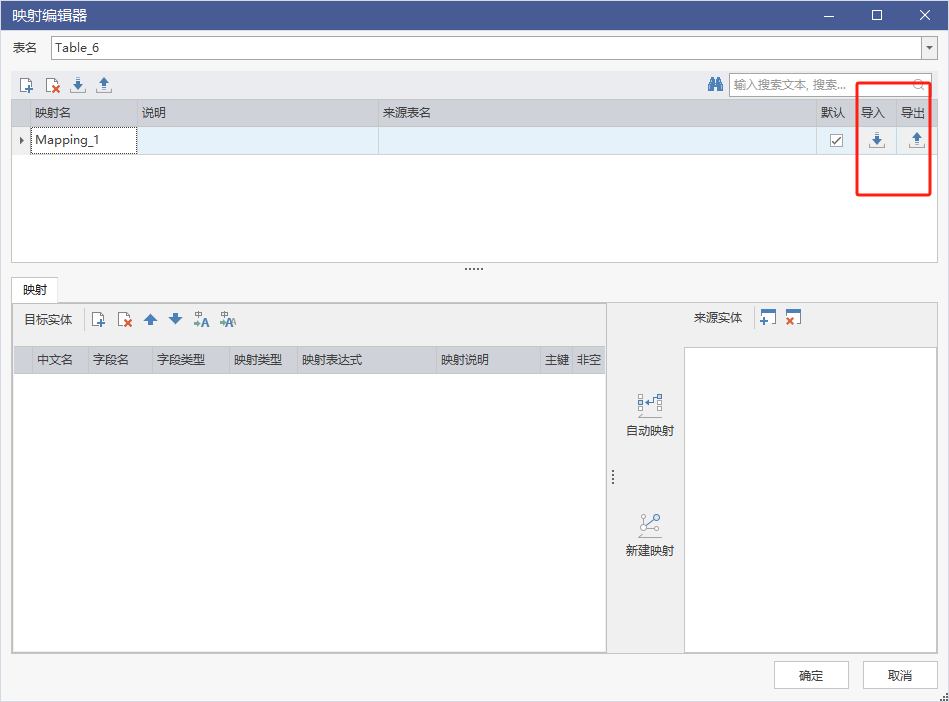
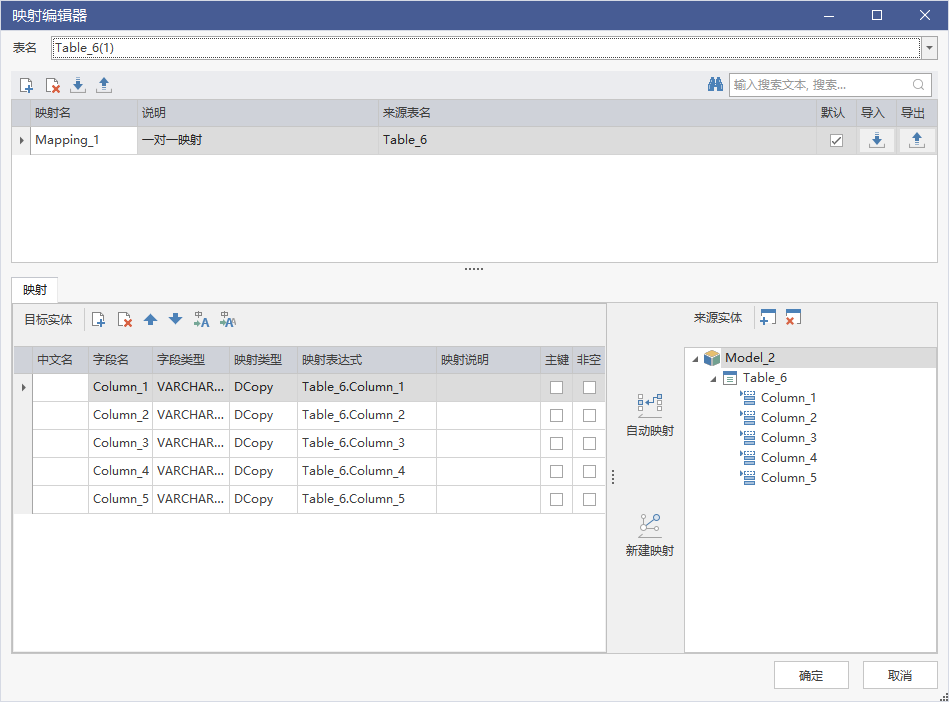
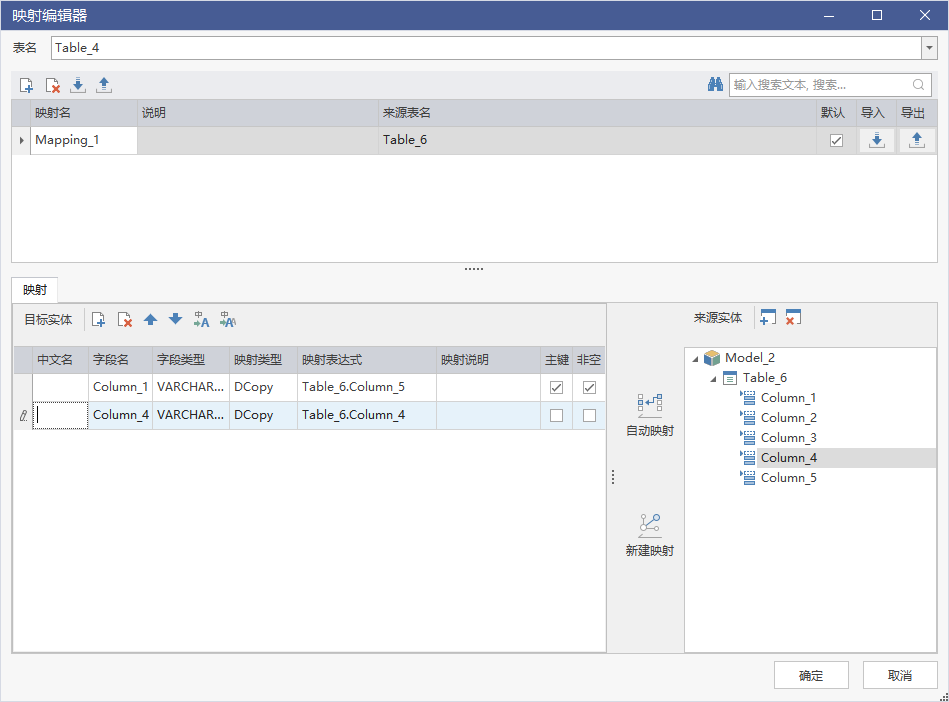
手动创建映射
选中一个表,右键点击【映射编辑】,进入映射编辑页面,在该页面可以创建映射,也可以导入导出维护映射 。
关系模型
DDM支持企业基于关系模型进行数据库设计,通过将数据组织成二维表的形式,并利用表之间的关联关系来表示数据之间的联系。在DDM中,企业可以方便地进行ER实体编辑、Subtype关系映射等操作,确保数据库模型能够准确反映业务实体及其之间的关系。同时,DDM还提供了自动落标、自动中英文翻译、数据库类型自动转换等实用功能,大大提高了数据库设计的效率和准确性。
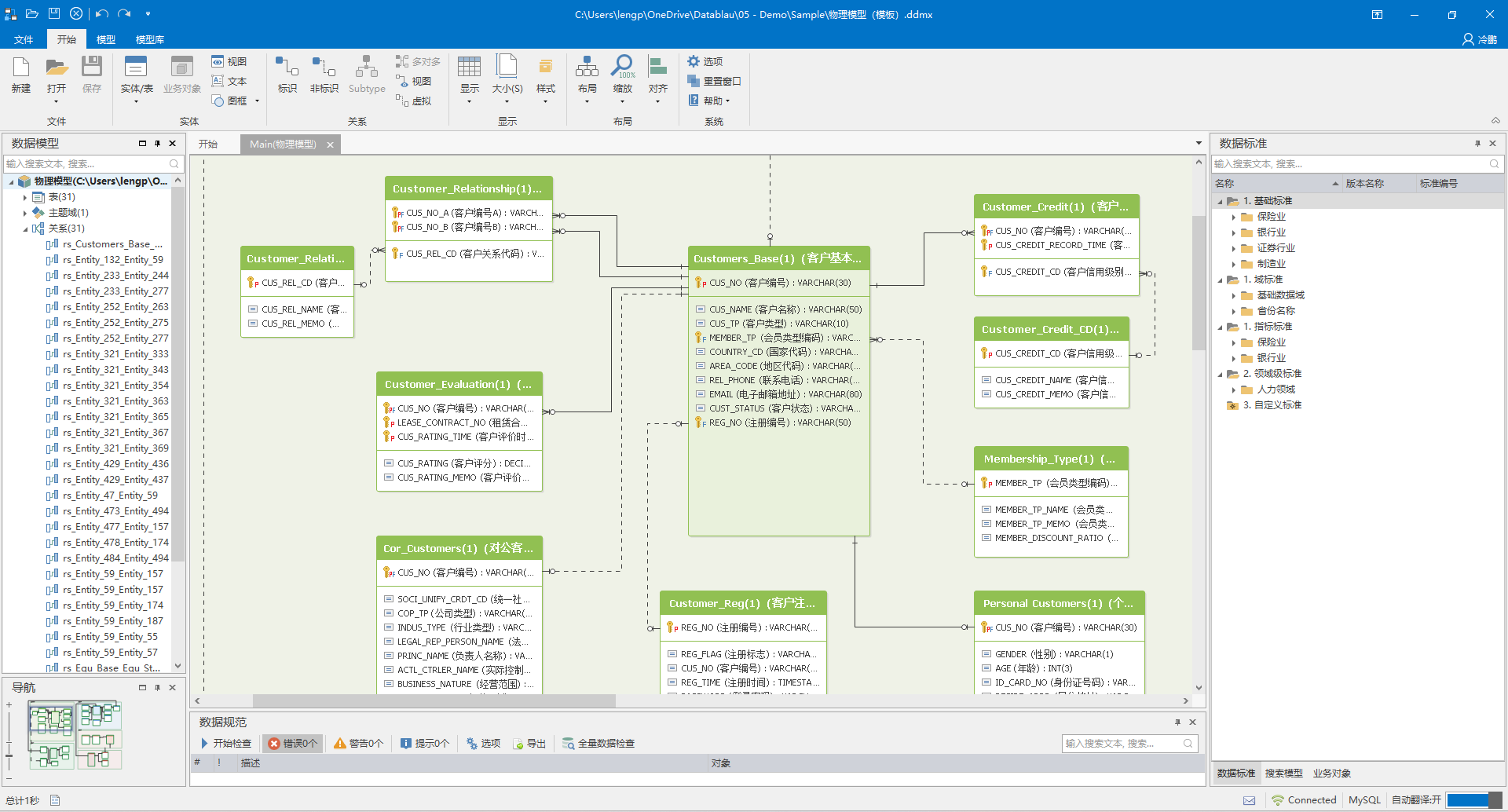
模型概述
关系型数据库建模是基于关系模型的一种数据建模方法,通过将数据组织成二维表(关系)的形式,利用表之间的关联关系(如主键 - 外键关系)来表示数据之间的联系。它旨在将现实世界中的复杂数据结构和关系转化为适合在关系型数据库中存储、管理和操作的数据模型。
核心要点
- 实体和属性(Entities and Attributes):首先,识别系统中的主要实体(例如客户、订单、产品)及其属性。每个实体可以转换为一个数据库表,实体的属性对应表中的列。
- 关系(Relationships):确定实体之间的关系,包括一对一、一对多和多对多关系。关系可以通过外键在表之间建立联系。
- 主键和外键(Primary Keys and Foreign Keys):主键是用于唯一标识表中每一行的字段,外键是用于建立表之间关系的字段。例如,订单表中的客户ID可以作为外键,连接到客户表中的客户ID。
- 规范化(Normalization):规范化是将数据分解成多个表,以减少数据冗余和提高数据一致性。通常包括第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。例如,第一范式要求消除重复数据,确保每个字段都是不可再分的基本数据单元。
- 设计约束(Design Constraints):设计数据库时需要考虑各种约束,如唯一性约束、检查约束等,以确保数据的完整性和合法性。